


مدیریت شیرپوینت
High-Availability روشی را که برای مقاوم سازی server farm خود در برابر hardware failures انجام می دهید، توصیف می کند. به عبارت دیگر، High-Availability به این معنی است که کاربران می توانند در صورت خرابی یک جزء در farm ، همچنان به شیرپوینت دسترسی داشته باشند. در مقابل، disaster recovery به فرآیندهایی اطلاق میشود که برای جلوگیری از از دست رفتن دادهها در صورت بروز نقص سختافزاری یا نرمافزاری، انجام میدهید. هنگام طراحی استراتژی های High-Availability و disaster recovery برای SharePoint farm، درک رویکردهای مختلف مورد نیاز برای هر لایه منطقی در farm مهم است. High-Availability برای database tier مستلزم درک این است که چطور high availability،SQL Server و الزامات مرتبط را فراهم میکند.
شما می توانید با افزودن سرورهای بیشتری که SQL Server را اجرا می کنند، در برابر از دست رفتن database servers محافظت کنید. با استفاده از SQL mirroring، SQL Failover Clustering یا AlwaysOn Availability Groups می توانید چندین سرور SQL را پیکربندی کنید تا high availability برای پایگاه داده ها فراهم شود. اکنون میتوانیم هر یک از این گزینهها را با جزئیات ببینیم.
استفاده از SQL Mirroring برای High-Availability
SQL database mirroring گزینه ای برای در دسترس قرار دادن پایگاه داده ها در SQL Server 2008 R2 است (در، high availability ،SQL Server 2012 از طریق AlwaysOn Availability Groups انجام می شود. Database mirroring یک کپی اضافی از یک پایگاه داده به نام mirror را بر روی یک SQL Server جایگزین ارائه می دهد. ;این mirrored database به طور خودکار با تغییراتی که در نسخه اصلی database رخ می دهد به روز می شود. mirrored database server به عنوان failover database server نیز شناخته می شود. Mirroring اطلاعات گزارش تراکنش را از سروری که نسخه اصلی پایگاه داده را در خود نگه می دارد به سروری که mirror را نگه می دارد می فرستد، جایی که گزارش ها به طور مداوم پخش می شوند، به طوری که mirror copy آخرین تغییرات را منعکس می کند.
با SQL Mirroring، فقط SQL Server اصلی می تواند تغییرات را در هر زمان در database بنویسد.
SQL Mirroring تنها از یک mirror برای ارائه دو نسخه از database در مجموع پشتیبانی می کند.
SQL Mirroring از سه حالت availability زیر پشتیبانی می کند.
High-Availability mode
این حالت از synchronous mirroring استفاده می کند به طوری که تراکنش ها در Database اصلی تنها پس از کپی کردن موفقیت آمیز تراکنش ها در mirror انجام می شود. این حالت نیاز به استفاده از یک SQL Server اضافی به عنوان یک سرور شاهد دارد، که هم Principal server و هم mirror server را نظارت میکند، اگر میخواهید قابلیتهای آپدیت خودکار اختیاری ارائه کنید.
High safety mode
این حالت همچنین از synchronous mirroring استفاده می کند، اما نیازی به استفاده از سرور شاهد ندارد. این حالت داده های روی mirror را تضمین می کند، اما نمی تواند خطای خودکار را ارائه دهد و باید به عنوان یک warm standby option در نظر گرفته شود. این بدان معنی است که در صورت خرابی در سرور اصلی، راه حل به طور خودکار نمی تواند کنترل شود و برای آنلاین کردن راه حل نیاز به انجام تنظیمات مجدد است.
High performance mode
این حالت از asynchronous mirroring استفاده میکند، که به مدیر عامل اجازه میدهد تا در اسرع وقت تراکنشها را انجام دهد، بدون اینکه منتظر بماند تا mirror نسخههایی از تراکنشها را دریافت کرده باشد. این به این معنی است که mirror ممکن است به طور کامل با اصل به روز نباشد، بنابراین ممکن است برخی از داده ها در صورت شکست از بین بروند. با این حال، این حالت اجازه می دهد تا عملیات عملیاتی بالاتری از تراکنش های اصلی انجام شود. این حالت نیازی به سرور شاهد ندارد زیرا failover یک فرآیند دستی است.
Failover database server
شیرپوینت از failover خودکار با SQL Server Mirroring با استفاده از گزینه Failover database server ارائه شده هنگام ایجاد new content databases ،new web applications یا new service applications پشتیبانی می کند. اگر failover database server را مشخص کنید و شیرپوینت نتواند پس از چندین بار تلاش مجدد با سرور اصلی SQL تماس بگیرد، شیرپوینت به طور خودکار سعی می کند به همان پایگاه داده در failover database server متصل شود، که mirror آن خواهد بود. SQL synchronous mirroring را می توان در نسخه استاندارد SQL Server پیکربندی کرد و هیچ الزام خاصی برای Windows Server ندارد. تنها با استفاده از نسخه های SQL Server Enterprise یا Datacenter می توانید انعکاس ناهمزمان SQL را پیکربندی کنید.
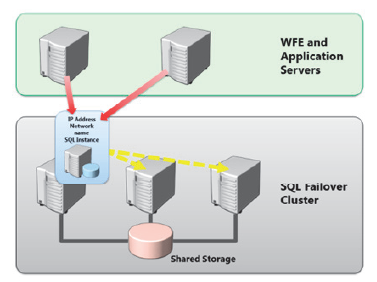
استفاده از Failover Clustering برای SQL High-Availability
SQL Server Failover Clustering مبتنی بر Windows Server Failover Clustering (WSFC) است. Clustering از خرابی سخت افزار سرور پایگاه داده واقعی محافظت می کند، در حالی که Mirroring از خرابی خود داده محافظت می کند. استفاده از WSFC و یک پلتفرم ذخیرهسازی مشترک، مانند iSCSI یا ذخیرهسازی مبتنی بر کانال فیبر، شما را قادر میسازد تا یک نمونه با قابلیت دسترسی بالا از SQL Server ایجاد کنید. یک نمونه با دسترسی بالا از SQL Server شامل عناصری مانند نام شبکه نمونه و آدرسهای IP، علاوه بر پایگاه دادههایی است که روی آن نمونه اجرا میشوند. این بدان معناست که برنامههایی مانند شیرپوینت که در پایگاههای داده در حال اجرا هستند، نیازی به پیکربندی تنظیمات سرور failover ندارند. اگر سروری در کلاستر از کار بیفتد، کل نمونه SQL، از جمله دسترسی به فضای ذخیرهسازی، نام شبکه، آدرس IP و سرویسهای پشتیبانی کننده ویندوز، به گره دیگری در خوشه نمیرسد و برنامه میتواند بدون پیکربندی مجدد به پایگاههای داده دسترسی پیدا کند. به دلیل نیاز به ویژگی WSFC، خوشه بندی Failover SQL نیاز دارد که SQL Server بر روی نسخه های Windows Server Enterprise یا Datacenter نصب شود. می توانید از SQL Server Standard Edition برای ایجاد یک خوشه Failover دو گره استفاده کنید. شما می توانید از SQL Server Enterprise edition برای ایجاد یک خوشه failover با استفاده از حداکثر تعداد گره های پشتیبانی شده توسط سیستم عامل استفاده کنید. Windows Server 2008 R2 از کلاسترها تا 16 گره پشتیبانی می کند. ویندوز سرور 2012 از کلاسترها تا 64 گره پشتیبانی می کند.
استفاده از AlwaysOn Availability Groups برای High-Availability
SQL Server 2012 مکانیسم جدیدی با قابلیت دسترسی بالا به نام AlwaysOn Availability Groups ارائه می دهد. AlwaysOn Availability Groups با مدیریت کپی های متعدد از یک پایگاه داده به روشی مشابه شبیه سازی پایگاه داده، اما به طور قابل توجهی بهبود یافته، حفاظت با قابلیت دسترسی بالا را برای پایگاه های داده ارائه می کند. هنگامی که یک گروه دسترسی AlwaysOn ایجاد می کنید، نمونه ای از SQL Server 2012 را به عنوان نسخه اولیه برای آن گروه پیکربندی می کنید. نسخه اولیه کپیهای خواندن/نوشتن پایگاههای داده را میزبانی میکند که میخواهید در دسترس نگه دارید. سپس می توانید بین یک تا چهار نمونه SQL Server 2012 را به عنوان نسخه های ثانویه پیکربندی کنید. هر نسخه ثانویه میزبان یک کپی از هر یک از پایگاههای داده از نسخه اولیه است که در گروه در دسترس بودن قرار دارند. اگر نسخه اولیه در دسترس نباشد، میتوانید به صورت دستی یا خودکار نقش نسخه اولیه را در فرآیندی به نام failover به یکی از کپیهای ثانویه منتقل کنید. پایگاههای دادهای که میخواهید در گروه دسترسپذیری در دسترس قرار دهید، باید از مدل بازیابی کامل استفاده کنند. ماکت اولیه با کپی کردن تراکنش ها روی کپی های ثانویه، کپی های ثانویه را به روز نگه می دارد. AlwaysOn Availability Groups از دو حالت در دسترس بودن زیر پشتیبانی می کند.
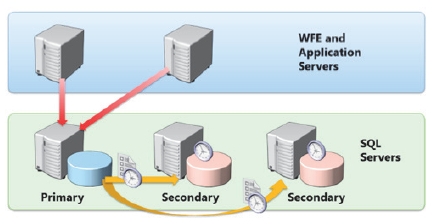
Synchronous-commit mode
در synchronous-commit mode، زمانی که یک client پایگاه داده را به روز می کند، replica اولیه تغییر را در گزارش محلی خود می نویسد و تغییر را در replica های ثانویه خود کپی می کند. سپس primary replica منتظر میماند تا secondary replicas قبل از انجام تراکنش و ارسال یک تأییدیه برای مشتری، تأیید کنند که تراکنش را در گزارشهای خود نوشتهاند. Synchronous-commit mode تضمین میکند که پایگاههای دادهای که بخشی از availability group در کپیهای اولیه و ثانویه هستند، همیشه همگامسازی میشوند تا از عدم از دست رفتن داده در صورت خرابی اطمینان حاصل شود. با این حال، این فرآیند منجر به کاهش عملکرد می شود در حالی که نسخه اولیه منتظر تایید است.
Asynchronous-commit mode
در asynchronous-commit mode، زمانی که پایگاه داده یک به روز رسانی دریافت می کند، replica اولیه تغییرات را در گزارش خود می نویسد و به روز رسانی ها را به نسخه های ثانویه خود ارسال می کند. این حالت منتظر تایید نسخه های ثانویه نیست و باعث بهبود عملکرد می شود. با این حال، اگر یک failover رخ دهد، کپیهای ثانویه ممکن است همه تراکنشهای اولیه را نداشته باشند و برخی از دادهها از بین بروند. کلاینت ها با استفاده از یک شنونده گروه در دسترس که از نام DNS، شماره پورت TCP و یک یا چند آدرس IP تشکیل شده است، به پایگاه های داده در یک گروه در دسترس متصل می شوند. استفاده از شنونده نیاز به پیکربندی مجدد کلاینت ها برای اتصال به نسخه اصلی جدید در صورت خرابی را برطرف می کند. گروههای AlwaysOn Availability از انواع مختلفی از failover پشتیبانی میکنند که میتوانند خودکار یا برنامهریزی شده باشند و ممکن است بسته به اینکه پایگاههای اطلاعاتی در دسترس در حالت synchronous-commit mode یا asynchronous-commit mode اجرا میشوند، از دست رفتن داده را تضمین نکنند. Automatic failover فقط در synchronous-commit mode در دسترس است.
استفاده از Log Shipping برای High-Availability
در log shipping ،SQL Server، یک راه ساده برای پیاده سازی warm standby solution برای کمک به سناریوهای disaster recovery و high-availability ارائه می دهد. Warm standby به این معنی است که راه حل نمی تواند به طور خودکار در صورت خرابی در سرور اصلی کار کند و برای آنلاین کردن راه حل نیاز به انجام تنظیمات مجدد است. با این حال، یک warm standby solution بسیار سریعتر از restoring databases از نسخه پشتیبان اجرا می شود و معمولاً پیاده سازی آن نسبت به hot standby solution، مانند mirroring، که می تواند به طور خودکار با شکست مواجه شود، ارزان تر است. Log shipping شامل پشتیبان گیری دوره ای از گزارش تراکنش و کپی کردن نسخه پشتیبان در یک سرور ثانویه است که یک نسخه از پایگاه داده را نیز در خود نگه می دارد.
سرور ثانویه log backup را بازیابی می کند تا زمانی که می خواهید کپی ثانویه را شروع کنید، log ها آماده پردازش باشند. این فرآیند backup، کپی و restore توسط یک سری کارهای SQL Server Agent خودکار میشود. میتوانید مشخص کنید که log backups به دفعات انجام شده و به سرورهای ثانویه منتقل میشوند تا تعیین کنید چقدر از نسخه ثانویه عقب است. با این حال، مهم است که توجه داشته باشید که با ارسال گزارش، همیشه خطر از دست رفتن داده ها وجود دارد، زیرا هیچ راهی برای تضمین سازگاری تراکنش بین نسخه های اولیه و ثانویه وجود ندارد. Log shipping مفید است زیرا الزامات یکسانی برای transactional consistency و clustering وجود ندارد، بنابراین log shipping میتواند در زیرشبکههای مختلف و اغلب بین سرورهای SQL در مکانهای فیزیکی مختلف، مانند یک disaster recovery site، استفاده شود. همچنین میتوانید کپیهای ثانویه را به گونهای پیکربندی کنید که load delay داشته باشند، که از ایجاد تغییرات در یک recent time window، مانند هشت ساعت، در پایگاه داده ثانویه جلوگیری میکند. این بدان معناست که نسخه ثانویه همیشه هشت ساعت از نسخه اصلی عقب خواهد بود. این پیکربندی می تواند در جایی که می خواهید از پایگاه داده در برابر user error یا logical corruption محافظت کنید مفید باشد. در چنین حالتی، مدیر میتواند انتخاب کند که به نسخه ثانویهای که هنوز اقدامی را که میخواهید از آن اجتناب کنید پردازش نکرده است، سوئیچ کند. Log shipping مستلزم استفاده از مدلهای بازیابی کامل یا انبوه در پایگاه داده است. میتوانید از ارسال گزارش با نسخههای SQL Server Standard و Enterprise که روی نسخه استاندارد Windows Server اجرا میشوند، استفاده کنید. هیچ نیاز خاصی برای Windows Server Enterprise برای پیکربندی ارسال گزارش وجود ندارد.
پشتیبانی با High-Availability برای SharePoint Databases
اگرچه SQL Server از چندین فناوری با دسترسی بالا پشتیبانی میکند، اما همه این فناوریها برای پایگاههای داده شیرپوینت مناسب نیستند. قبل از برنامهریزی استراتژی high-availability و disaster Recovery برای شیرپوینت، مهم است که بدانید کدام فناوریهای high-availability برای استفاده در farm شما مناسب هستند.